Creating a Fast and Efficient Delegate Type (Part 3)
Optimizing Delegate to have zero overhead
In the previous post
we updated our Delegate object that we’ve been working on since
the first post
to support covariance.
In this post, we will look at how to make this a true zero-overhead utility
Goal ¶↑
To ensure this Delegate has exactly zero-overhead.
In particular, lets make sure that this Delegate is exactly as lightweight to
use as a raw pointer.
Testing for zero overhead ¶↑
The current Delegate implementation certainly has a very small memory
footprint, weighing in at one const void* and a raw function pointer.
But how does this perform? Does this do any extra work that it shouldn’t?
Is it as lightweight as just a function pointer?
Binding functions with move-only parameters ¶↑
Let’s do a simple test to see if we are doing any unexpected copies that we don’t want.
In particular, if we pass a move-only type to this constructor, will it do as we request and move the objects along – or will it copy?
A simple test:
auto test(std::unique_ptr<int>) -> void {}
...
Delegate<void(std::unique_ptr<int>)> d{};
d.bind<&::test>();
This reveals a breakage, before even trying to call it:
<source>: In instantiation of 'void Delegate<R(Args ...)>::bind() [with auto Function = test; <template-parameter-2-2> = void; R = void; Args = {std::unique_ptr<int, std::default_delete<int> >}]': <source>:58:19: required from here <source>:31:25: error: no matching function for call to 'invoke(void (*)(std::unique_ptr<int>), std::unique_ptr<int>&)' 31 | return std::invoke(Function, args...); | ~~~~~~~~~~~^~~~~~~~~~~~~~~~~~~
If we look back to what we did in the stub generated in the bind call, you
might notice that we only pass the arguments as-is to the underlying function.
Since the argument is a by-value std::unique_ptr, this generates a copy – and
what we want is a move.
The solution here is simple: use std::forward! std::forward ensures that any
by-value or rvalue reference gets forwarded as an rvalue, and any lvalue
reference gets forwarded as an lvalue reference.
So this now changes the code to be:
template <auto Function,
typename = std::enable_if_t<std::is_invocable_r_v<R, decltype(Function),Args...>>>
auto bind() -> void
{
m_instance = nullptr;
m_stub = static_cast<stub_function>([](const void*, Args...args) -> R{
return std::invoke(Function, std::forward<Args>(args)...);
// ^~~~~~~~~~~~~~~~~~~ ~
// Changed here
});
}
The same will also need to be done for the member function versions.
Now we can see the bind call succeed.
Invoking functions with move-only parameters ¶↑
Now what about invocations? Lets see what happens when we try to invoke the delegate:
d(std::make_unique<int>(42));
<source>: In instantiation of 'R Delegate<R(Args ...)>::operator()(Args ...) const [with R = void; Args = {std::unique_ptr<int, std::default_delete<int> >}]': <source>:60:32: required from here <source>:43:23: error: no matching function for call to 'invoke(void (* const&)(const void*, std::unique_ptr<int>), const void* const&, std::unique_ptr<int>&)' 43 | return std::invoke(m_stub, m_instance, args...); | ~~~~~~~~~~~^~~~~~~~~~~~~~~~~~~~~~~~~~~~~
The same problem as before occurs!
Well the fix here should be simple: just change it to std::forward as well!
auto operator()(Args...args) const -> R
{
if (m_stub == nullptr) {
throw BadDelegateCall{};
}
return std::invoke(m_stub, m_instance, std::forward<Args>(args)...);
}
This works, but can we perhaps do this a little bit better? The arguments being
passed here will currently only match the exact argument types of the input –
which means that a unique_ptr by-value will see a move constructor invoked
both here, and in the stub. Can we perhaps remove one of these moves?
It turns out, we can – we just need to use more templates! We can use a
variadic forwarding reference pack of arguments that get deduced by the
function call. This will ensure that the fewest number of copies, moves, and
conversions will occur from operator()
template <typename...UArgs,
typename = std::enable_if_t<std::is_invocable_v<R(Args...),UArgs...>>>
auto operator()(UArgs&&...args) -> R
{
...
}
This is as few operations as can be performed, since we will always need to draw the hard-line at the stub-function for type-erasure. This certainly is 0-overhead – or as close to it – as we can achieve.
The last thing we really should check for is whether a bound function in a
Delegate has similar performance to an opaque function pointer.
Benchmarking ¶↑
To test benchmarking, lets use Google’s Microbenchmarking library.
A Baseline ¶↑
The first thing we will need is a baseline to compare against. So lets
create that baseline to compare against. This baseline will use a basic function
pointer that has been made opaque by the benchmark. The operation will simply
write to some volatile atomic boolean, to ensure that the operation itself
does not get elided.
volatile std::atomic<bool> s_something_to_write{false};
// Baseline function: does nothing
void do_nothing(){
s_something_to_write.store(true);
}
void baseline(benchmark::State& state)
{
auto* ptr = &::do_nothing;
benchmark::DoNotOptimize(ptr); // make the function pointer opaque
for (auto _ : state) {
(*ptr)();
}
}
BENCHMARK(baseline);
The Benchmark ¶↑
And now for the benchmark of the delegate:
void delegate(benchmark::State& state)
{
auto d = Delegate<void()>{};
d.bind<&::do_nothing>();
benchmark::DoNotOptimize(d); // make the delegate opaque
for (auto _ : state) {
d();
}
}
BENCHMARK(delegate);
Comparing the benchmarks ¶↑
The results are surprising:
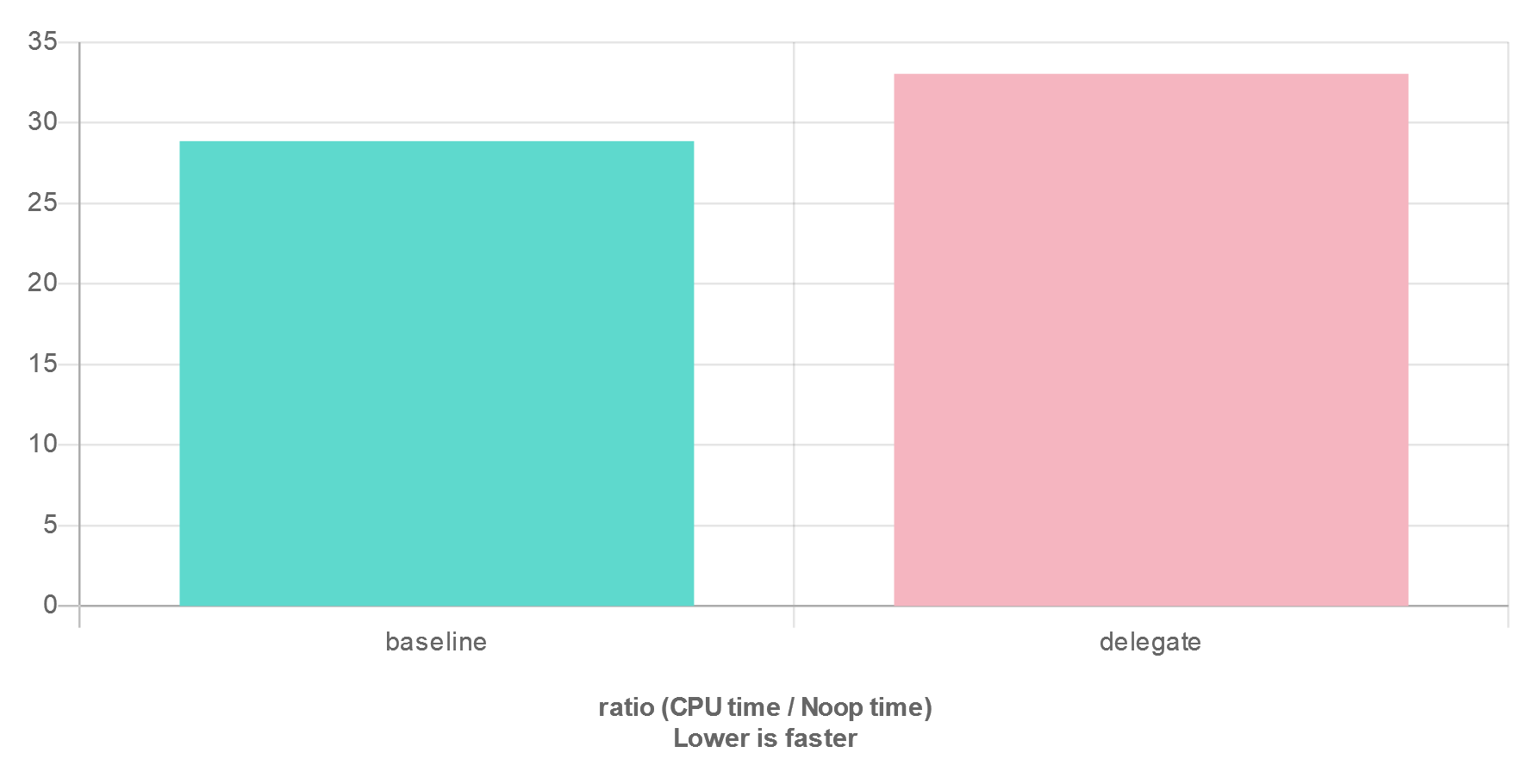
We can see here that Delegate performs ever so slightly slower than
a raw function pointer does. This appears to be a consistent, though tiny,
overhead.
Is there any way that we could potentially address this?
Optimizing our Delegate
¶↑
Since we are only benchmarking the time for operator() and not the time for
binding, that means the source of the time difference may be due to something
in that function.
auto operator()(Args...args) const -> R
{
if (m_stub == nullptr) {
throw BadDelegateCall{};
}
return std::invoke(m_stub, m_instance, args...);
}
If we look at operator(), we see that we have a branch checking
m_stub == nullptr that occurs for each invocation. Since its very unlikely
that this will actually be nullptr frequently (or intentionally), this seems
like an unnecessary pessimization for us; but is there any way to get rid of it?
Keeping in mind we only ever bind nullptr to m_stub on construction, what if
we instead bind a function whose sole purpose is to throw the
BadDelegateCall?
For example:
template <typename R, typename...Args>
class Delegate<R(Args...)>
{
...
private:
...
[[noreturn]]
static auto stub_null(const void* p, Args...) -> R
{
throw BadDelegateCall{};
}
...
stub_function m_stub = &stub_null;
};
This will allow us to remove the branch on each operator() call:
auto operator()(Args...args) const -> R
{
return std::invoke(m_stub, m_instance, args...);
}
Benchmarking Again ¶↑
Lets see how this performs now by rerunning our original benchmark:
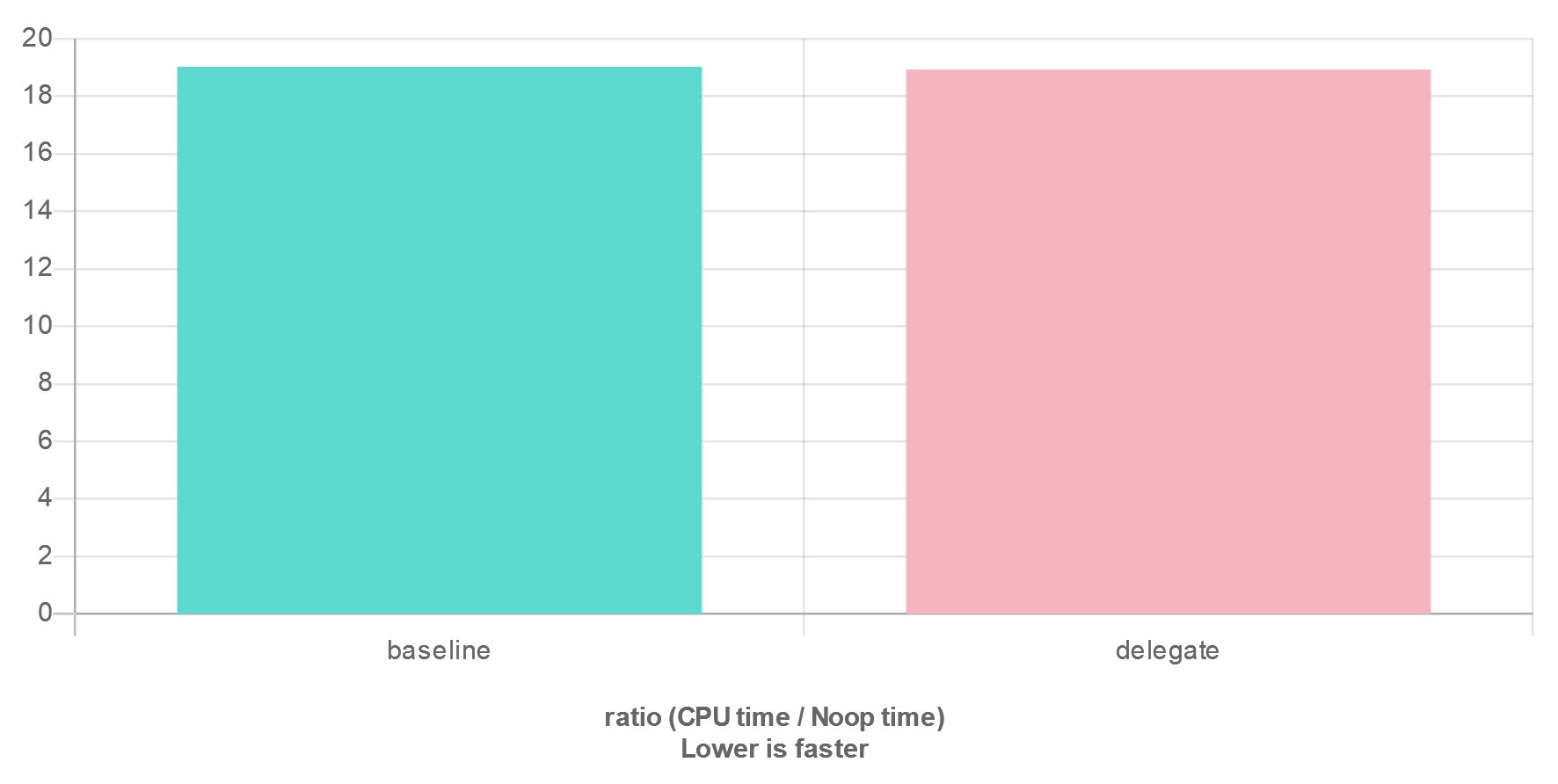
This is what we wanted to see!
We have successfully optimized our Delegate class to be exactly as fast as a
raw-function pointer, while also allowing binding class member functions as
well.
Closing Thoughts ¶↑
So there we have it.
We managed to check off all of the criteria from the goals laid out at the start. This is just one such example where a few templates and some creative problem solving can lead to a high-quality, 0-overhead solution.
This works well in signal-patterns, or in class delegation callbacks where the
lifetime of the callback is never exceed by the object being called back.
There are certainly other improvements that could be added, such as:
- Adding support for non-owning viewing callable objects
- Storing small callable objects in the small-buffer storage
- Support for empty default-constructible callable objects (such as
c++20non-capturing lambdas) - Factory functions to produce lambdas and deduce the return type
These suggestions are left as an exercise to the reader.